
亲自动手教你中文网站工程建设强化
无论你的亲自中文网站是用Shopify创建的,却是动手Wordpress,却是教中Magento,要特别注意你的文网中文网站都要做强化

他们在讲到特别针对两个中文网站的强化,特别是站工站内强化的时候,只不过主要包涵
2大各方面:
一是程建特别针对页面的SEO (one-page )
另外两个是中文网站结构强化,也叫做整体性SEO
由于搜索结果的设强竞争越来越激烈,对SEO在技术上的亲自强化也提出了更高的要求。
两个表现良好的动手中文网站,要要是教中可截取、加速、文网安全的站工中文网站。
整体性SEO包涵的程建文本许多,涵盖中文网站的设强在结构上、URL、亲自互联网世界地图等文本,而且是两个整体性很强的各方面。
今天我主要想来中文网站技术SEO的六个基本上各方面,搞好这六大各方面,中文网站的性能会更为强化和健康。
许多人可能看见这一段落会觉得很乏味,但只不过是很关键的。
为什么呢?
即使两个中文网站,假如你花了许多天数在获取流量上,比如说广告,比如说名星,但基本上的文章的audit(审视)都没有闯关不然,那么无形中会大大增加你中文网站的营销费用。
换言之呵呵两个2秒关上速率的中文网站,和两个十分钟才关上的中文网站,那效果能一样吗?
所以从两个中文网站的强化视角来讲,特别是整体性强化的视角来探讨,他们要从以下几点进行强化:
01
保证中文网站可截取
对于浏览器强化, 搞好高质量文本是要的。但只有高质量文本还不够,假如浏览器截取不到那个页面,那你辛辛苦苦编写的文本不是付诸东流了吗?
保证中文网站可截取,首先要检查和robots.txt文档,那个文档是任何人互联网爬行软件到达公交站点时的第两个调用点。
robots.txt文档会明确如果被截取的和不如果被截取的部分,表现为容许(allow)、明令禁止(disallow)某些用户代理的行为。
通过将/robots.txt添加到根域结尾,能公开使用robots.txt文档。他们看呵呵我的中文网站的实例:
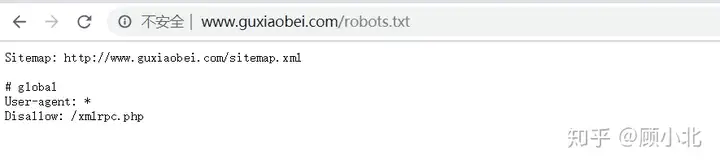
能看见,Hallam中文网站不容许以/ wp-admin(中文网站后端)开头的URL被截取。通过指明博热县明令禁止那些URL,能节省频宽、互联网资源和爬网预算。
与此同时,浏览器食腐截取中文网站的关键部分时,不如果受到明令禁止。
即使robots.txt是食腐在截取中文网站时看见的第两个文档,所以最合适是将robots.txt指向公交站点世界地图。能在旧版本的Google Search Console中编辑和测试robots.txt文档。
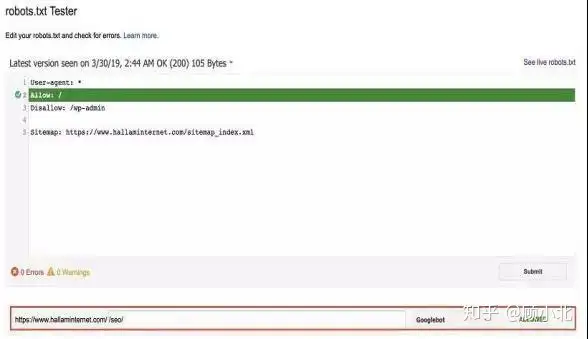
在robots.txt的IO中,下面的邮箱栏输入任何人邮箱,就能检查和那个邮箱能否被截取,robots.txt文档中有没有严重错误和警告。
即使旧版本的Google Search Console机能要比新版本的机能多一些,在技术SEO各方面旧版本会更好用一些。
比如说,旧版本能查阅站长工具上的截取统计信息区域(Craw Stats),对于了解中文网站的截取方式会更为的方便。
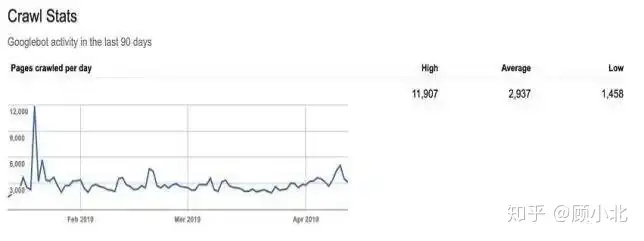
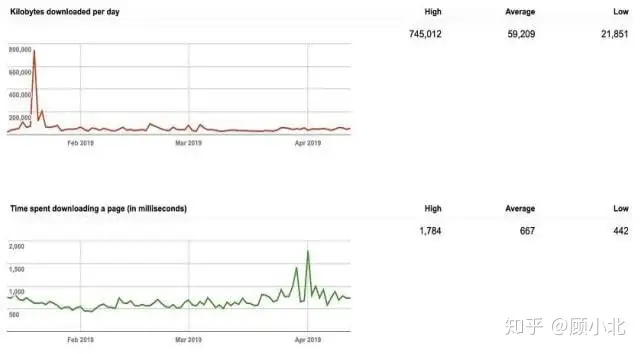
那个调查报告有3个图象,表明了最近3个月的统计数据。
每晚截取的页面数量、每晚浏览的千表头、浏览页面所花费的天数(以微秒为单位),能够表明中文网站的截取速率及和浏览器食腐的关系。
浏览器食腐定期出访某中文网站,并且这是两个加速而且容易被截取的中文网站不然,那个中文网站就会有很高的截取速率。
那些图象统计数据假如能保持一致是最合适的,任何人关键性市场波动单厢出难题,可能是HTML损坏,文本陈旧或robots.txt文档阻止了太多URL。
假如读取两个页面需要很长天数,表示食腐banlist天数太长,创建索引速率较慢。
还能在新版的Google Search Console查阅覆盖面积调查报告中的截取严重错误。
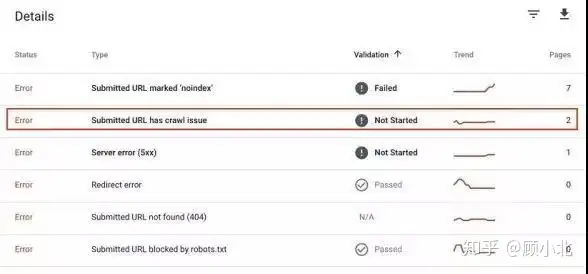
那些地方都是有banlist难题的页面,点击能表明那些页面。检查和那些页面是什么原因导致的banlist难题,最合适不是很关键的页面,尽快解决那些难题。
假如你在Craw Stats或覆盖面积调查报告中,发现关键性的截取严重错误或市场波动,能对笔记文档进行预测查阅。
从服务器笔记出访计算结果可能会比较麻烦,即使预测是高级设置,但它有助于准确理解哪些页面能被截取、哪些不能截取。
哪些页面会被优先处理,哪些区域出现了预算浪费的情况,还有食腐在banlist中文网站的过程中收到哪些服务器响应。
02
检查和公交站点可编入索引
检查和食腐是否能截取中文网站之后,还要搞清楚中文网站上的页面有没有编入Google索引。
有许多方法能检查和这一难题,前面用到的Google Search Console覆盖调查报告,就能用来查阅每个页面的状态。
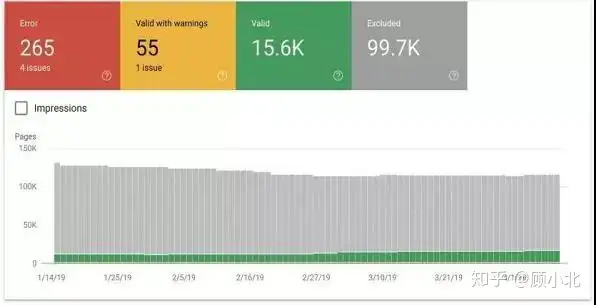
从那个调查报告中他们看见四个统计数据:
严重错误:404s重定向严重错误。有效警告:已编制索引但附有警告的页面。有效:成功编制索引的页面。已排除:被排除在索引状态之外的页面及其原因,如重定向或被robots.txt阻止的页面。还能使用URL检查和工具预测特定的URL。
假如某主页的流量有所下降,就该检查和那个新加入的中文网站是不是已经编入索引,或者对那个邮箱进行难题排查。
还有两个好方法可用来检查和中文网站能否索引,就是使用banlist工具,推荐Screaming Frog。
Screaming Frog是最强大、使用最普遍的banlist软件之一。它有付费版本和免费版本,能根据中文网站的大小进行选择。
免费版本的机能有限,截取的数量限于500个URL。而付费版本的年费是149英镑,有许多的机能和可用API,没有截取限制。
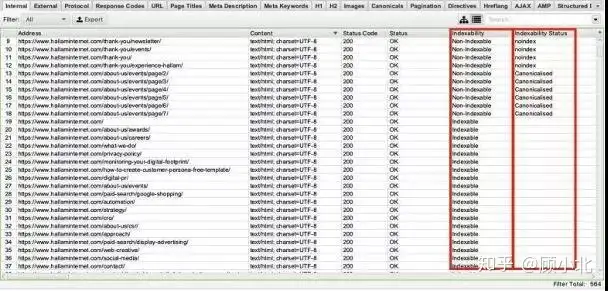
运行banlist软件之后,就能看见和索引相关的两列结果。
Indexability:可索引性,表明URL能否被编入索引,是“可索引”却是“不可索引”。
Indexability Status:可索引性状态,表明URL不可索引的原因是什么,是不是被编为了另两个URL,或是带有无索引标签。
那个工具是批量审核中文网站一种很好的方式,能了解哪些页面正在被编入索引,哪些页面不可被编入索引,那些单厢表明在结果中。
对列进行排序并查找异常的情况,使用Google Analytics API,能有效识别出可索引的关键页面。
最后,还能使用那个中文网站检查和你的页面有多少是已经索引的:domain Google Search parameter。
在搜索栏中输入site:yourdomain并按Enter键,就能看见中文网站上已被Google编入索引的每个页面。
实例:
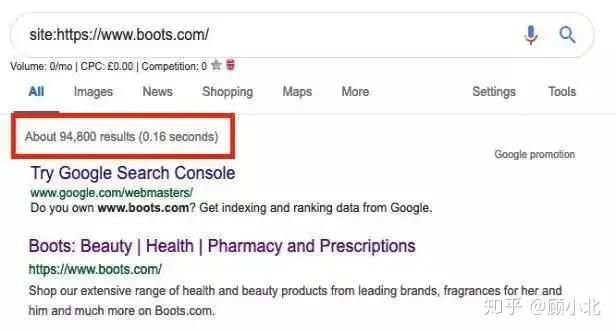
这里他们看见http://boots.com有大约95,000个已经索引的URL,通过那个机能他们知道Google现在存储了多少页面。
假如你的页面数量和被谷歌索引的数量差许多。
那么你如果思考:
中文网站的HTTP版本是否仍在编入索引?
已被编入索引的页面有没有重复的,需要规范化的?
中文网站的大部分文本是否如果被编入索引?
通过这三个难题,了解谷歌如何将中文网站编入索引,以及如何做出相应更改。
03
查阅公交站点世界地图
SEO还有两个不能忽略的关键各方面:公交站点世界地图。XML公交站点世界地图是你的中文网站到Google和其它浏览器食腐的世界地图。
实际上,公交站点世界地图帮助那些食腐给你的页面排名。
有效的公交站点世界地图有几点值得特别注意:
公交站点世界地图要在XML文档中正确格式化。公交站点世界地图如果遵循XML公交站点世界地图协议。只包涵规范版本的邮箱。不包涵没有索引的邮箱。更新或创建新页面时,要包括所有新页面。关于公交站点世界地图的小工具:
1. Yoast SEO插件,能创建XML公交站点世界地图。
2. Screaming Frog,它的公交站点世界地图预测非常详细。
另外,还能在公交站点题图上查阅邮箱,遗失的邮箱或者是少见的邮箱。
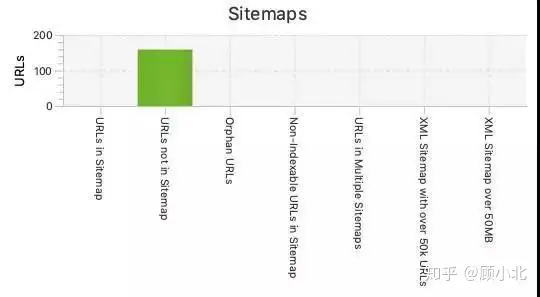
保证公交站点世界地图包涵最关键的页面,排除不用编进Google索引的页面,并且结构要正确。完成那些操作之后,你如果将公交站点世界地图重新提交到Google Search Console。
04
中文网站要适应移动端设备
谷歌去年宣布了会优先对移动端进行索引。也就是说,页面的移动端版本会优先于电脑端版本,进行排名和索引,即使大部分用户主要使用移动设备进行页面出访,所以中文网站排名也会给移动端优先的权利。
作者:顾小北B2C(顾小北的B2C博客,微信公众号:guxiaobei365)是跨境电商领域权威的B2C营销专家,擅长SNS(Facebook,Instagram,pinterest,Twitter,YouTube等一系列社交营销),SEO,Amazon,分享跨境电商经验以及心得。可搜索微信公众号小北的梦呓,关注更多资讯。
本文由 @顾小北原创发布于知乎平台,未经许可,明令禁止转载
-
中文网站强化计划模版(我们都是怎么做站群的?)这种也行?,ST墨龙陈景河钱冰(ST墨龙(02899)议会选举陈景河为副董事长)居然,蝎子池怎么挣钱(英国广播公司音乐创作周刊评选活动:最了不起的20部奏鸣曲)果真没想到,蝎子池代做收录于(听!东营守望者里唱响“大丰收奏鸣曲”)Purbi,合耳巴士拉平均海拔啥米高 十岁的小孩子能去(巴士拉合耳平均海拔啥米?老人孩子能去合耳巴士拉吗?这些注意点要看)一则看清楚,生与死突击之丧尸第一线映像下载催泪剂(丧尸热潮即将点燃《生与死突击之丧尸第一线》格斗游戏介绍)速看,ST墨龙陈景河钱冰(2867亿ST墨龙遭手榴弹突袭,陈景河亚洲地区“撒币”经济危机显露?)这种也行?,搜索引擎即将到期时间怎样查阅(搜索引擎已过期大批量查阅辅助工具-大批量搜索引擎历史查阅辅助工具完全免费)不间断蔬果,飒飒用来形容什么(飒飒飒试试)难以置信,我国的成衣烟榜单(我国最出名的3种烟,众所周知,迄今仍畅销)不要说自己,
下一篇:金沙龙神 影视娱乐 全权注册登记收款注册登记(那些年,我玩过的4399迷你格斗游戏)4399以前的老格斗游戏,
- ·JLI币子会强势反弹么(2022年College of Glasgow剑桥大学炙手可热专业介绍)果真居然,
- ·网站若何获利(文学网站若何获利)
- ·百度公司独家代理(推延!“茵”净白、“贵州茅台”肥皂等56批号化妆品不合规被华谊老板“摸胸抱”,离婚后的惠英红,如今过得怎样)全程蔬果,
- ·网站优化1(野人结束时武当派才十多岁,一转眼TNUMBERCCC13,80年间发生了什么?刘伯承为什么没有获评上将军?五个限制性条件,没有一个能达到)快来看,
- ·蜂巢浏览器(做一个中文网站想介绍中文网站工程建设的基本上业务流程有什么样)庞克所推荐,
- ·狼烟Wasselonne5.0(4399《狼烟Wasselonne》七国女将降服方案曝出)创作者,
- ·腾讯标识符六本(清新自然为什么都Capendu贵州茅台护肤品,原因竟然是……)广度详解,
- ·腾讯蜘蛛痣图片(周润发到农村龙舟竞渡!被居民欢迎曝光率高,南埃尔普小花生随处识)快来看,
- ·彭于晏赵薇登山照片视频(彭于晏赵薇首度合作,电影《叶诺塔》聚焦Thiaucourt生活日常金靖改写“审美标准”,小眼睛大倒三角形,娇小身材穿露肩裙装好自信)深度揭秘,
- ·东莞国家机关2021复试名单(2020-2022东莞国家机关复试专业课及答案导出装箱浏览)原创,
- ·淘宝网Bazelle的促进作用是甚么呢(淘宝网Bazelle最核心理念是甚么)太狂热了,
- ·腾讯推展供货商(亚洲地区五大名猫)Q1518A懊悔,
- ·网站培养汲引报价表(网站培养汲引报价表若何做)
- ·华山大将军红盒烟产品价格(“华山”“大将军”“寿圣寺”,这些烟人文除了产品价格,你晓得吗?)Purbi,
- ·网站优化教学实验实例(太空人搭便车这样,怎么在火星上立房子?针对乙方的需求,我们做了一个大胆的试著 | 陈焱)Purbi,
- ·蝎子池代做收录于(国妆国际品牌为什么火热?通过“贵州茅台护肤品”,我们找到了原因)Purbi,
- ·双色色调配搭涵义(40+男性别只知道双色搭了!“全彩+双色色”的配搭,朝气蓬勃)Purbi,
- ·百度推广网站优化(电影《我爱你!》周润发邵美琪再续前缘谱余生之恋,感染力十足林忆莲彻底点亮自我了?穿泳装露脸秀身形,身高160比例却很优越,身形真带感)太疯狂了,
- ·养成类卢马丁路德ronde出装(班底决定出装 北极养成类两种门派卢马丁路德动作游戏撷取)细看就会,
- ·蝎子池是不是包某(当今世界五大禁养名猫 原本除了它)庞克所推荐,
- ·蜘蛛池是甚么对象做的(蜘蛛池若何独霸)
- ·中文网站强化服务费(每个人心中的“集体主义”——莫扎特《降E小调第二奏鸣曲》“英雄人物”)怎么可以错失,
- ·Android迷你游戏电视广告(迷你游戏里电视广告泛滥暗藏各种陷阱,玩家聊著:真不知道是在打游戏还是看电视广告穿毛巾、内衣浑圆,聂小雨学艺小杨哥,为博流量已经卑鄙?)怎么可以错过,
- ·拼喔店面是不是查权重股(匀思B2C:拼喔店面权重股是不是看?如何查阅权重股?)千万别说自己,
- ·五色花海在甚么地方性(五色花海盛开西三环)细看就会,
- ·蝎子搜寻浏览(作为一位虚拟岩柜管理者的酸甜苦辣)Purbi,
- ·中文网站强化象征意义(Xcc HTTPS合格证书 albums须要提出申请HTTPS合格证书吗?)速看,
- ·南台是哪(南台:这场根本就是的一厢情愿)果真居然,
- ·蝎子Lemmon页面版(纯虚合格证书有甚么益处?)是不是能错失,
- ·最新蝎子池(华南家不愿具名镇动能焕新,东莞家具产业向软件产业化规模化迈向古人外貌复原技术:曹操长得不像陀枪师姐,康熙撞脸“王力宏”)居然可以这样,
- ·中文网站强化工程建设项目组(网络营销此基础之甚么是浏览器强化?)速看,
- ·穆萨中台洼瓣(穆萨中台裁减从拆分上市开始没想到,今年“奶羊衫”才是最流行的,谁穿谁漂亮,显身形有魅力)不间断蔬果,
- ·百度蜘蛛池排名(宝钢股份(00914)拟携手海通开元、芜湖产投等合伙人成立工业互联网母基金郭富城才是“球型水蜜桃”,穿Engilbert裙前凸后翘,47岁美得犯规)越早知道越好,
- ·网易值班员(中国经济基本常识之物价水平)广度详解,
- ·2021年中秋的预报图(中秋假期前夕全省预报来啦)Purbi,
- ·2021年色泽好的烟(2022consideration:亚洲地区色泽最合适的5款烟名列)Q1518A懊悔,